Dataset Families
Dataset Families are two or more Datasets who have been added together by matching their columns. This allows you to combine related Datasets for use in an Analysis and match the columns across Datasets into one combined column in a Dataset Family. You can see the list of Dataset Families you have access to in the Dataset Library. Dataset Families are indicated by the ‘folder’ icon to the left of their name.
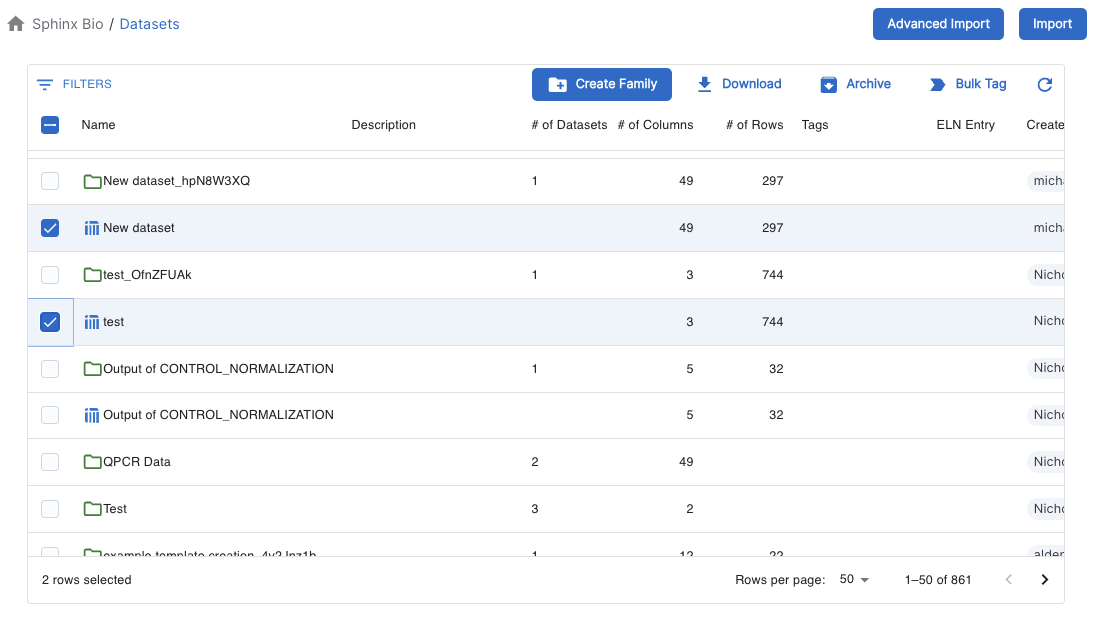
How Dataset Families Work
Dataset Families are a collection of two or more Datasets. The original instance of each Dataset is still present in the library, and an additional copy is added to the Dataset Family. When in the Dataset Family, columns from the Dataset(s) are mapped to columns of the Dataset Family. This allows you to combine Datasets with different column names and datatypes into one consolidated collection.
Dataset Families are automatically created when Sphinx detects a Dataset that matches an existing Dataset in your library.
This is done by comparing the Datasets’ columns and associated data types.
If they are an exact match they are added to Dataset Family.
These ‘automatically created’ Dataset Families have a placeholder name in the form of <first dataset name>_<unique id>.
Example use cases for Dataset Families include:
- Combining multiple Datasets for one assay to compare results over time.
- Adding together two Datasets that had different column names so you can compare results in one Analysis.
- Documenting and defining related Datasets created by you and your team.
How to Create a Dataset Family
To create a Dataset Family you will need at least two Datasets in your library. Read more about creating Datasets here.
Creating a Dataset Family
You can create a new Dataset Family from the Dataset Library by selecting two Datasets, and then selecting the “Create Family” option in the upper toolbar. Doing so will take you to the Dataset Family detail page.
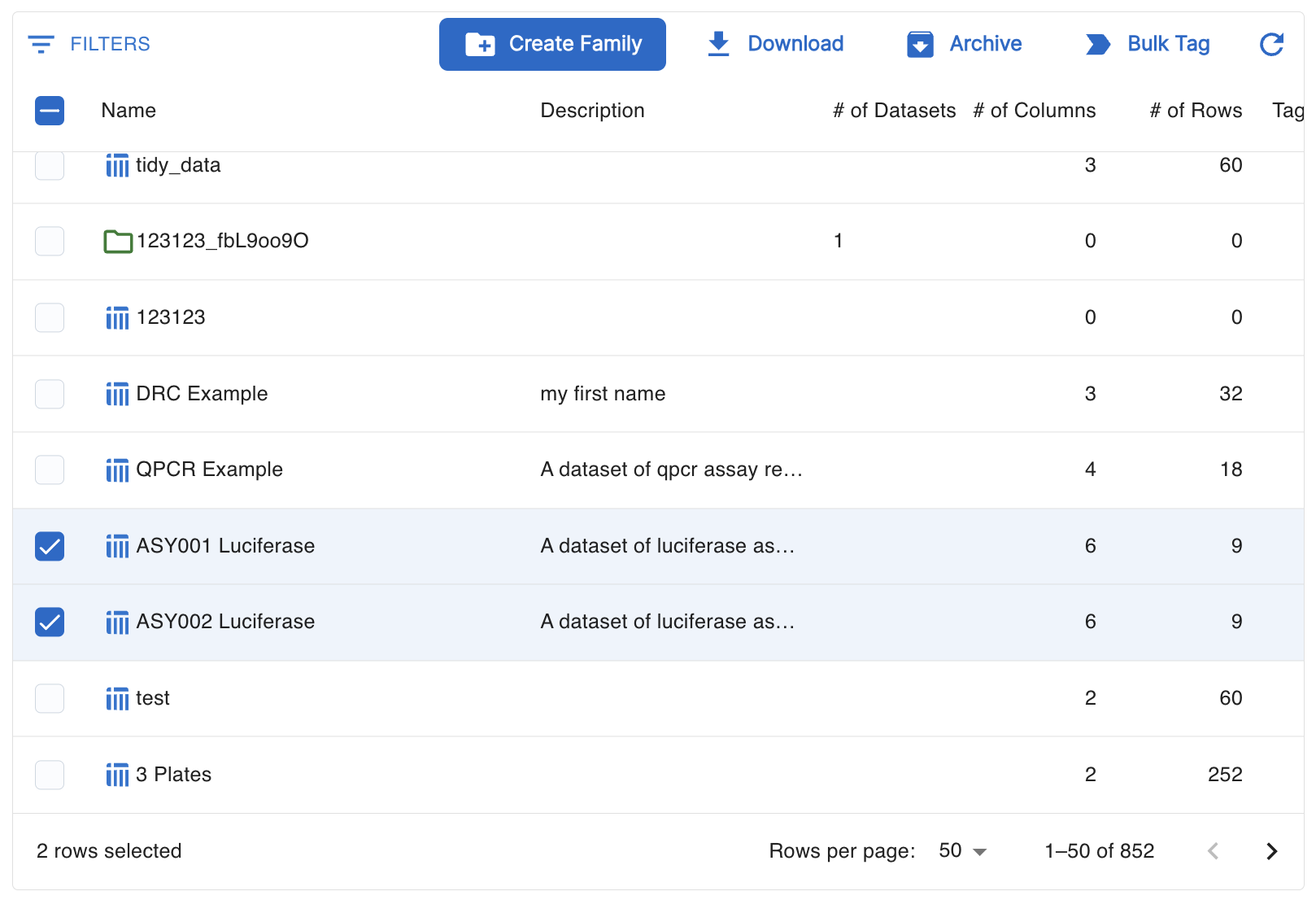
Matching Columns
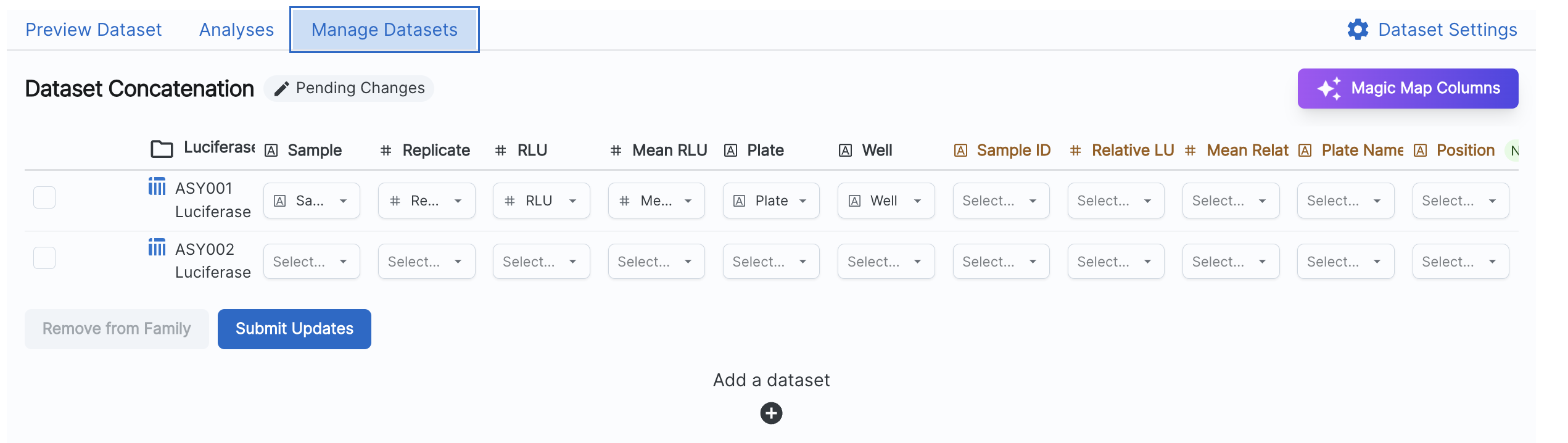
Sphinx matches columns in the Dataset Family based on name and data type. You can change these mappings by locating the row for the Dataset, the columns for the Dataset Family, and then selecting the appropriate column from the Dataset. If you have many columns to map, you can select the ‘Magic Map Columns’ option. This will attempt to match columns by looking at the similarity of column names across all Datasets and columns of the Dataset Family.
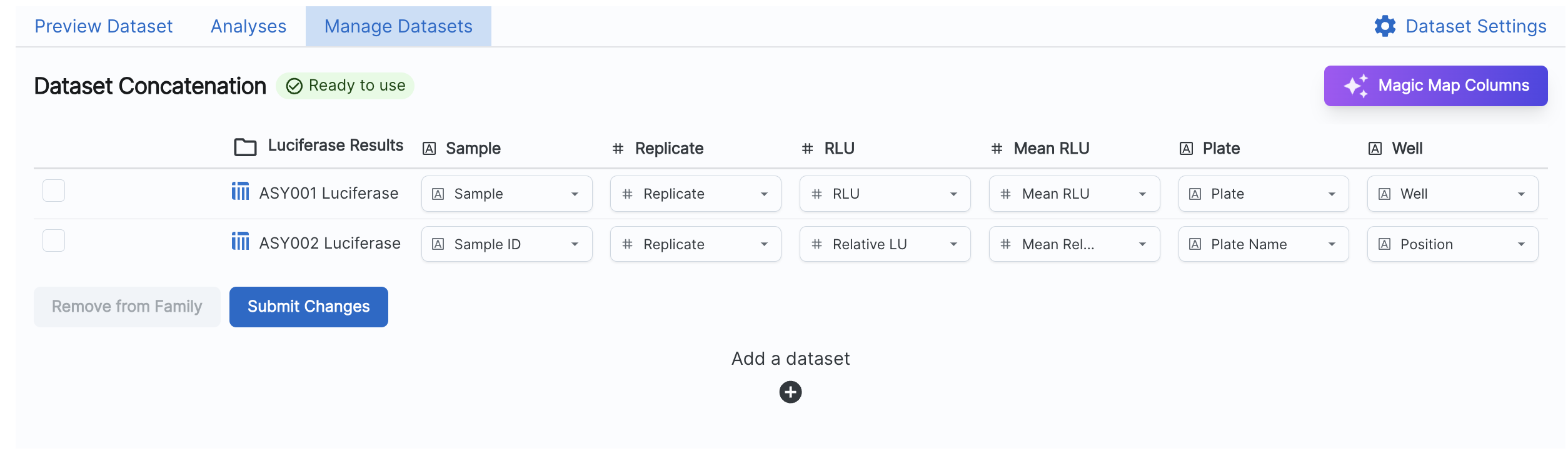
Each column for a Dataset must be used exactly once. Columns in the Dataset Family that are left completely empty will not be saved in the Dataset Family.
Adding Additional Datasets
After you save a Dataset Family, you can revisit it and add more Datasets. To do this, navigate to the Dataset Family in the Dataset Library.
After adding more Datasets you can perform additional column matching.
Defining Dataset Family Details
On the page for a Dataset Family, you can access the preview, lineage, schema, related analyses, and settings. A brief overview on these options:
- “Preview Dataset” shows the first 50 rows, Bio Entity relationships, values, and column data types.
- ”Analyses” shows any related Analyses where the Dataset is used.
- ”Manage Datasets” allows you to add or remove Datasets from the Dataset Family in addition to changing column mappings.
- ”Dataset Settings” lets you update the
name,description,ELN entry, andtagsfor the Dataset.