Pipeline
Pipelines allow you to define how to parse non-tabular data in a file. These can be saved for re-use as a Pipeline Templates or applied one-off for a data file. This allows you to upload files and create new Datasets immediately, without having to define rules for upload each time.
Check out Data and File Layouts for what type of data we can import.
Pipelines are made using the following steps.
Upload File(s)
To upload your file(s) you can click on “Upload Files” or drag and drop into the dotted area. You can add one or multiple files.

You can also link your ELN and import data from there. Please contact support if you’re interested in learning more about our integration with ELNs.
Once processed, each file, tab (if using an Excel file), and ELN entry will be show on the left side.
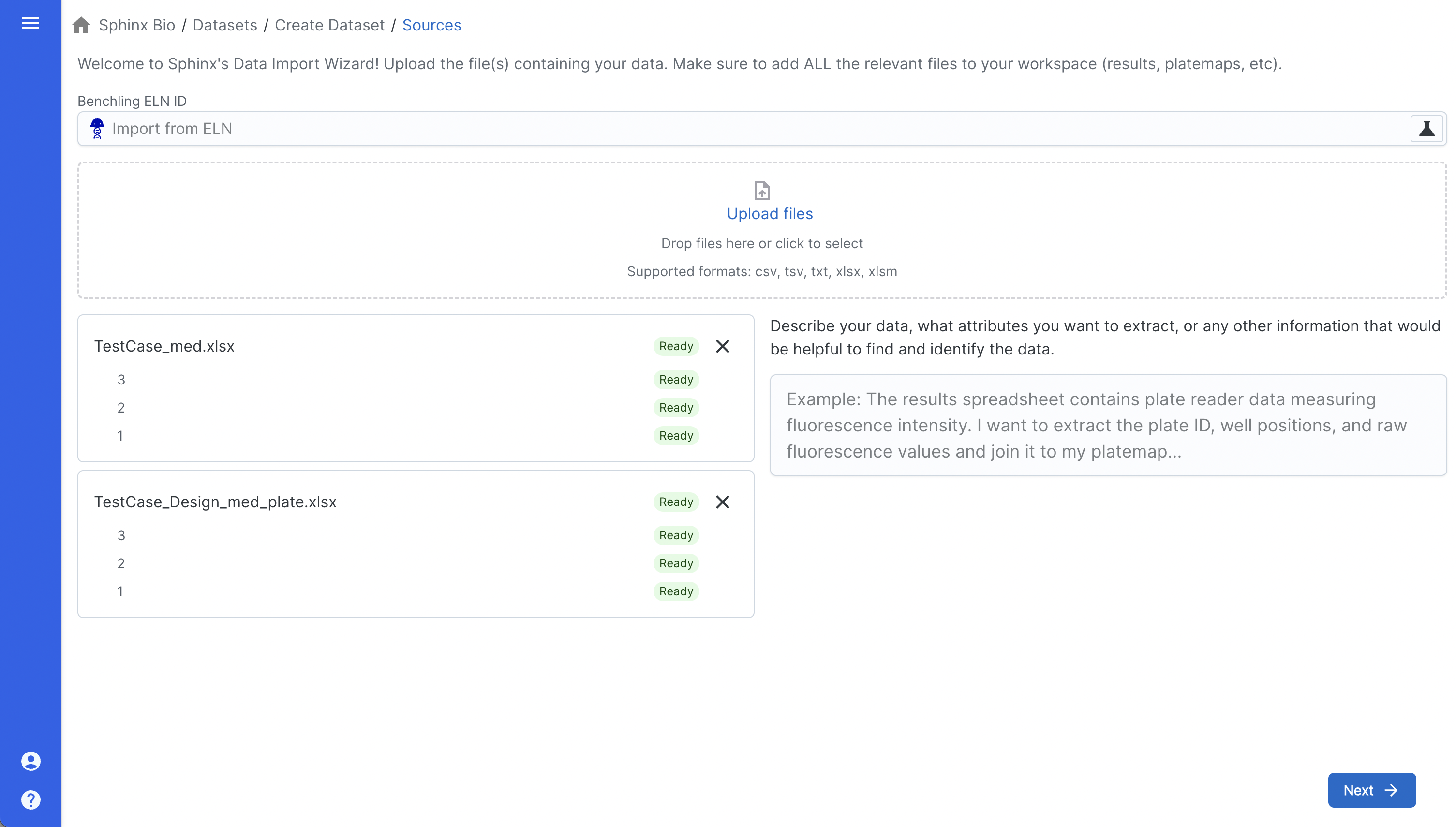
When you’ve added all of your files, click the “Next” button at the bottom right.
Extract Data
Inside a file are ‘data regions’ – which are the areas where your data are located.
If your file has multiple data regions, such as those described in Data and File Layouts you can add the file from your workspace any number of additional times to capture additional data regions.
Define File layouts Each data region will need to be selected and the type of the data region chosen. The below image shows a tabular layout as described in Data and File Layouts.

After selecting all of the data regions in all of your files, click “Next” at the bottom right to proceed.
Merge data
After you have defined your data file and data region you can define how they are merged together to create a single Dataset. Merging of data regions occurs by matching values in each selected column to values in a selected column in another data region (join). You can merge by one pair of columns or by many pairs of columns.
If using many pairs of columns all conditions must be met for the data to be merged, else they will appear as unconnected rows in the final dataset. Merging by matching the columns should be used when different variables exist across data files and need to be merged together, resulting in a wider table (outer joining).
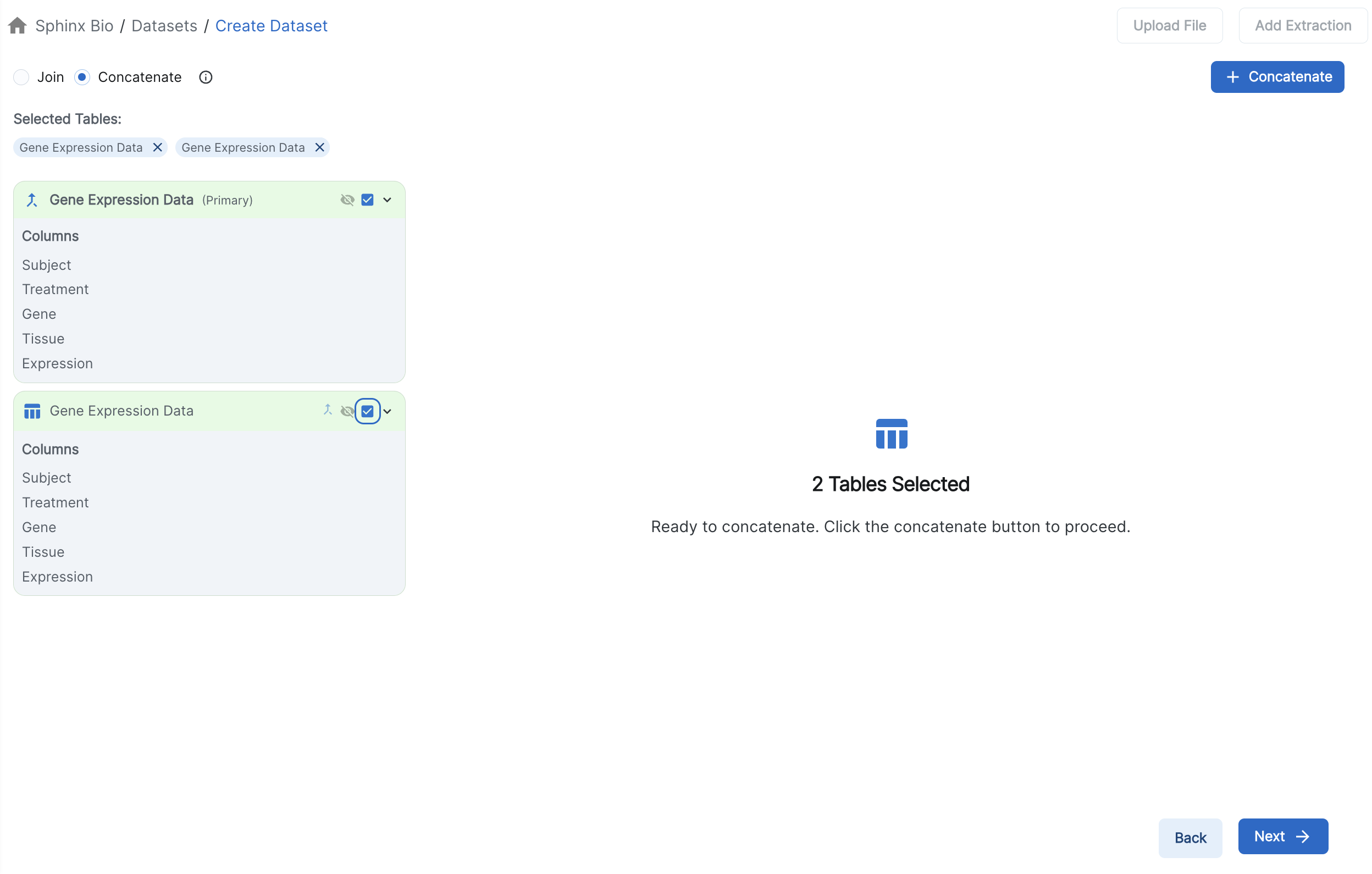
You can alternatively add a data region to your final Dataset as rows. This can be used when each data region contains the same kind of data, resulting in a longer table (concatenation). Once you are done merging all data regions into one, you can select “Finalize Dataset”.
Add Details and Finalize
Once in the finalize step, you can enter a name and click “Create Dataset”.
After creating the Dataset you can enter the Dataset Name, Dataset Description, Link to ELN entry, and Tags.
Completing this step will lead you to Dataset details page.
You can now use this Dataset to create an analysis.

If you want to reuse this pipeline later, make sure to follow the steps in Pipeline Templates to save it as a template.